aiNodes is a Python-based AI image/motion picture generator node engine that facilitates creativity in the creation of images and videos. The engine is fully modular and can download node packs on runtime. It also features RIFE and FILM interpolation integration, coloured background drop, and node-creation with IDE annotations. The installation process requires Python 3.10, Git, and an nVidia GPU with CUDA and drivers installed. AiNodes engine is an open-source desktop AI-based image/motion generator that supports various features such as Deforum, Stable Diffusion, Upscalers, Kandinsky, ControlNet, LORAs, Ti Embeddings, Hypernetworks, Background Separation, Human matting/masking, and Compositing, among others.
ProFusion is a new framework for customized text-to-image generation that preserves fine-grained image details without using regularization, as proposed in the paper. ProFusion includes PromptNet, an encoder network, and Fusion Sampling, a method that generates customized images based on a single user-provided image and text requirements. The paper explains how ProFusion works and provides experiments demonstrating its superior performance compared to existing approaches, while still meeting additional user-defined requirements.
OlaGPT is a newly developed framework that enhances large language models by simulating human-like problem-solving abilities. It incorporates six cognitive modules, including attention, memory, reasoning, learning, decision-making, and action selection. The model was evaluated on algebraic word problems and analogical reasoning questions, showing superior performance against existing benchmarks. OlaGPT is integrated with pre-existing models such as GPT-3 as base models, with different cognitive modules added. Although the framework has limitations that prevent it from providing a creative solution, it is a promising tool that could approximate the human brain model.
We propose the Asymmetric VQGAN, to preserve the information of conditional image input. Asymmetric VQGAN involves two core designs compared with the original VQGAN as shown in the figure. First, we introduce a conditional branch into the decoder of the VQGAN which aims to handle the conditional input for image manipulation tasks. Second, we design a larger decoder for VQGAN to better recover the losing details of the quantized codes.
The Open LLM Leaderboard tracks, ranks, and evaluates language models and chatbots based on various benchmarks. Anyone from the community can submit a model for automated evaluation on the GPU cluster, as long as it is a Transformers model with weights on the Hub. The leaderboard evaluates models on four benchmarks, including AI2 Reasoning Challenge, HellaSwag, MMLU, and TruthfulQA, to test reasoning and general knowledge in both zero-shot and few-shot settings.
StyleDrop is a technology that generates images in any desired style using text-to-image transformer, Muse. The technology captures nuances of user-provided styles such as design patterns and colour schemes. StyleDrop works by fine-tuning a few trainable parameters and improves the quality of generated images via iterative training with human or automated feedback. The technology can generate high-quality images from text prompts, and style descriptors are added during training and synthesis to improve the results. StyleDrop is easy to use and can be trained with brand assets. It can be used to generate alphabets with consistent styles in a single reference image. StyleDrop on Muse outperforms other methods in style-tuning for text-to-image models.
The Diffusion Explainer tool is an interactive webpage that allows users to generate an image from a text prompt. Users have control over various hyperparameters, including the seed and guidance scale, to customize the generated image. The text prompt should describe the desired image in detail to generate high-quality images. By changing the random seed, users can obtain different image representations. Moreover, adjusting the guidance scale can improve the adherence of the image to the text prompt but could limit the image's creativity. While the tool offers flexibility in creating images, it does not allow adjustments to other hyperparameters such as the total number of timesteps, image size, and the type of scheduler.
QLoRA allows fine-tuning of large language models on a single GPU. Using this method, they trained Guanaco, a family of chatbots based on Meta's LLaMA models, achieving over 99% of ChatGPT's performance. QLoRA reduces the memory requirement by quantizing models to 4 bits and adding low-rank adaptive weights. The team found that data quality is more important than quantity for fine-tuning, with models trained on OpenAssistant data performing better. Even the smallest Guanaco model outperformed other models, and the team believes that QLoRA will make fine-tuning more accessible, bridging the resource gap between large corporations and small teams. They also see potential for private models on mobile devices, enabling privacy-preserving fine-tuning on smartphones.
Mist is a powerful image preprocessing tool developed to protect images from being mimicked by AI-for-Art applications. It adds watermarks to images, making them unrecognizable and inimitable by state-of-the-art AI models. Mist has been open-sourced on GitHub and aims to create a collaborative community for developers and users to improve its performance. The advantages of Mist include robustness against noise purification methods and time efficiency, with the watermarking process taking only a few minutes. The tool is effective against various AI-for-Art applications such as textual inversion, dreambooth, scenario.gg, and NovelAI image2image. Mist is also robust to image transformations like cropping and resizing. The watermarking process is fast, with an image being processed within 3 minutes using default parameters.
BLIP-Diffusion is a new model for generating and editing images based on text prompts and subject images. Unlike previous models, it uses a pre-trained multimodal encoder to represent the subject, allowing for efficient fine-tuning and better preservation of subject details. The model enables the generation of new images based on text prompts and subject images, even without prior training on specific subjects. It also supports image manipulation, style transfer, and editing guided by subject images. The model is trained in two stages to learn subject representation and can be combined with other techniques for more control over the generation and editing process. Overall, BLIP-Diffusion provides a flexible and efficient approach to generate and edit images with specific subjects.
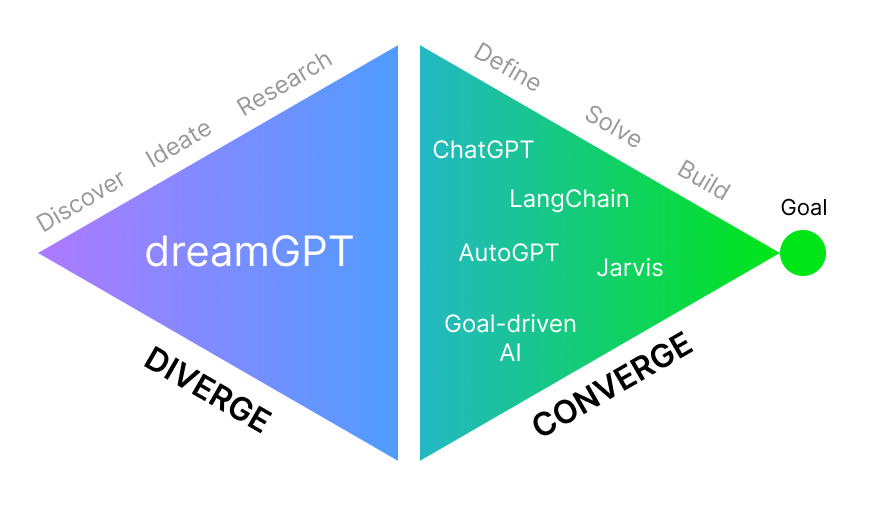
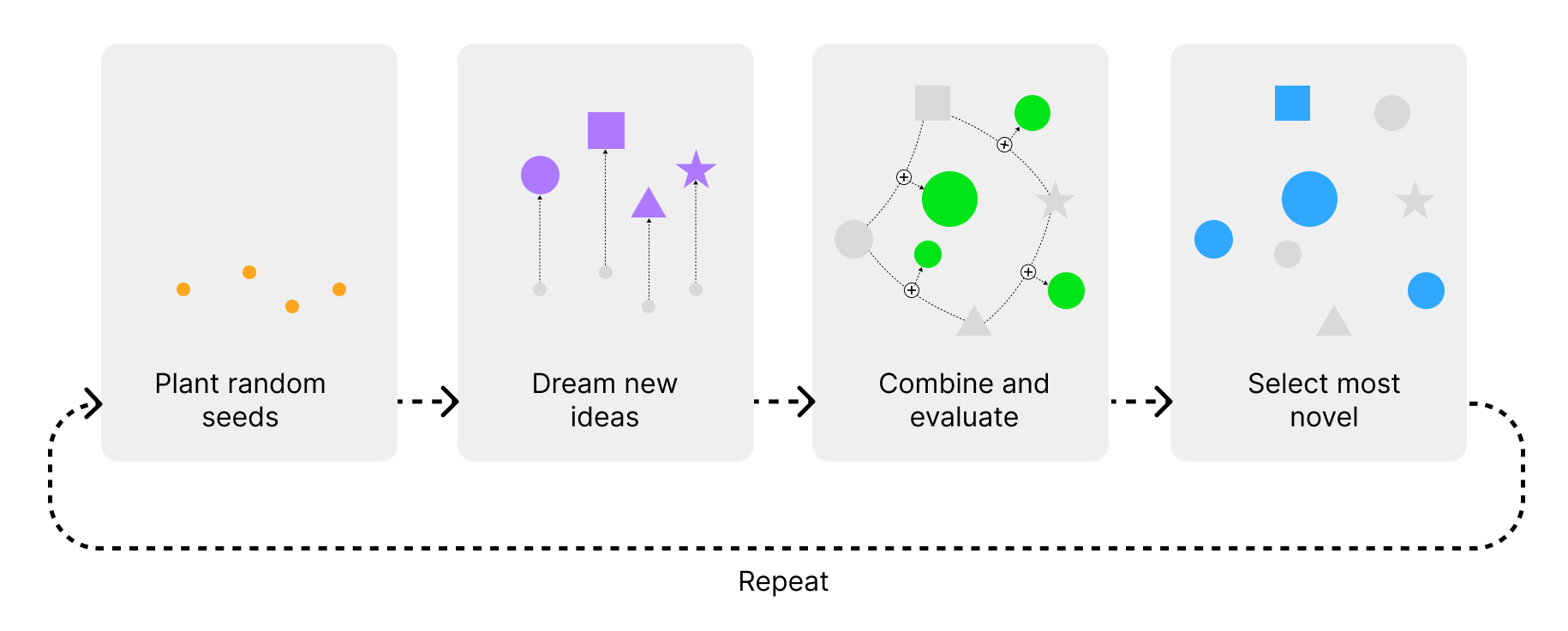
DreamGPT, the first GPT-based solution that uses hallucinations from LLMs for divergent thinking to generate new innovative ideas. Hallucinations are often seen as a negative thing, but what if they could be used for our advantage? dreamGPT is here to show you how. The goal of dreamGPT is to explore as many possibilities as possible, as opposed to most other GPT-based solutions which are focused on solving specific problems.
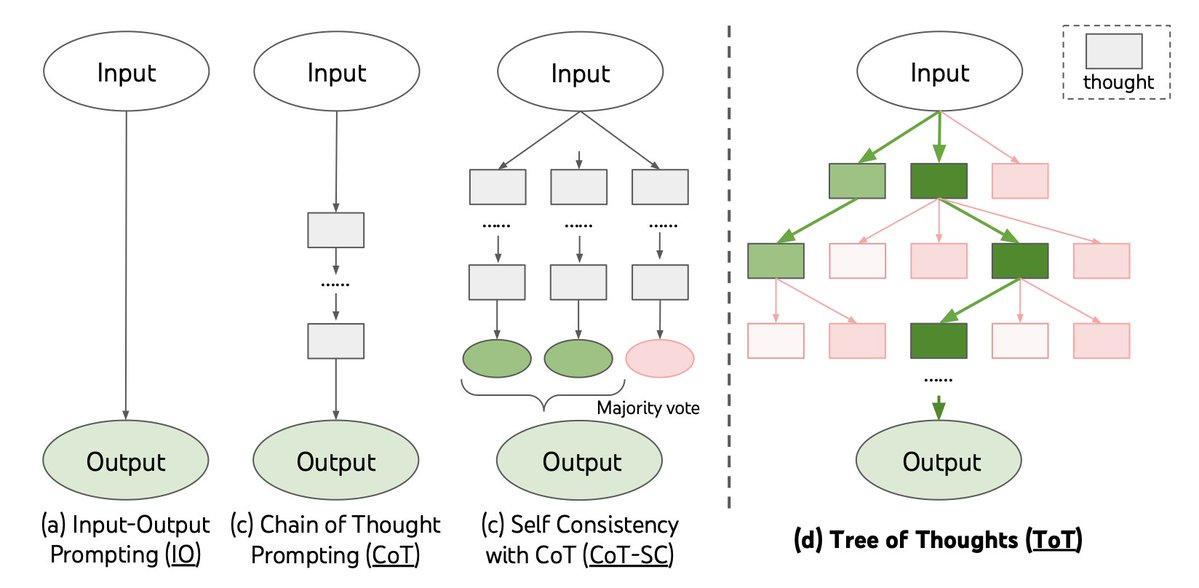
Tree-of-Thought (ToT) aims to enhance the problem-solving capabilities of large language models (LLMs) like GPT-4. The framework utilizes a deliberate 'System 2' tree search approach to tackle complex and general problems that LLMs struggle with. The author demonstrates significant improvements on three tasks: the game of 24, creative writing, and crosswords, which GPT-4 and CoT (chain of thought, another approach) find challenging due to the need for planning and searching. The limitations of token-by-token decoding, which lacks lookahead, backtrack, and global exploration, are highlighted as the reason for these difficulties. ToT achieves a tenfold performance boost by leveraging the LLM's ability to generate diverse intermediate thoughts, self-evaluate them through deliberate reasoning, and employ search algorithms like breadth-first search (bfs) or depth-first search (dfs) to systematically explore the problem space.
Composable Diffusion (CoDi) is a new generative model that can create different types of outputs (like language, images, videos, or audio) from various inputs. It can generate multiple outputs at the same time and is not limited to specific types of inputs. Even without specific training data, CoDi aligns inputs and outputs to generate any combination of modalities. It uses a unique strategy to create a shared multimodal space, allowing synchronized generation of intertwined modalities.
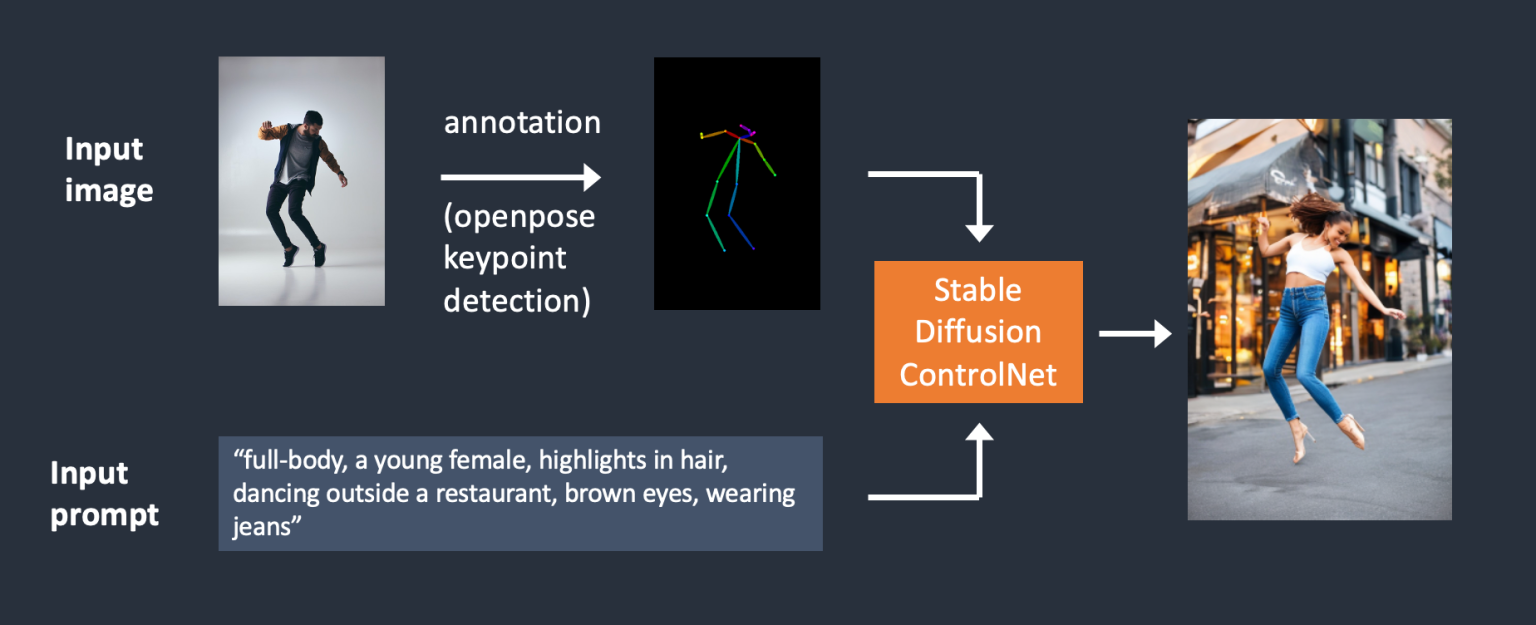
A comprehensive guide to ControlNet v1.1, a Stable Diffusion model that allows users to control image compositions and human poses based on reference images. The guide covers various aspects of ControlNet, including its installation on different platforms (Windows, Mac, Google Colab), settings, and common use cases.
The tutorial provides a comprehensive guide on creating consistent characters using Stable Diffusion (SD) and a Textual Inversion embedding. It outlines a five-step process, including generating input images, filtering them based on desired attributes, tagging them for training, training the embedding, and selecting a validated iteration. The tutorial emphasizes the importance of generating high-quality input images, filtering out unwanted variations, and fine-tuning the selection to achieve consistency. By following this tutorial, users can learn how to generate consistent characters with SD and create an embedding that reliably recreates the desired character across different poses, hairstyles, body types, and prompts.
SmartGPT is an experimental program meant to provide LLMs (particularly GPT-3.5 and GPT-4) with the ability to complete complex tasks without user input by breaking them down into smaller problems, and collecting information using the internet and other external sources.
DragGAN is a novel approach for controlling generative adversarial networks (GANs) in order to synthesize visual content that meets users' needs. It offers precise and flexible controllability over the pose, shape, expression, and layout of generated objects. Unlike existing methods that rely on manual annotations or 3D models, DragGAN enables interactive control by allowing users to "drag" any points of an image to reach desired positions. The approach consists of two main components: feature-based motion supervision and a point tracking approach utilizing discriminative GAN features. By utilizing DragGAN, users can manipulate diverse categories of images, such as animals, cars, humans, and landscapes, with realistic outputs even in challenging scenarios like occluded content and deforming shapes.
OP Vault is a versatile platform that allows users to upload various document types through a simple react frontend, enabling the creation of a customized knowledge base. It leverages advanced algorithms to provide accurate and relevant answers based on the content of the uploaded documents. Users can gain insights into the answers by viewing filenames and specific context snippets. The user-friendly interface of OP Vault makes it easy to explore the capabilities of the OP Stack, a powerful combination of OpenAI and Pinecone Vector Database. Moreover, OP Vault supports large-scale uploads, making it possible to load entire libraries' worth of books, thus expanding the scope of knowledge accessible through the platform. To ensure smooth operation, certain manual dependencies such as node (v19), go (v1.18.9 darwin/arm64), and poppler are required. With its diverse features, OP Vault offers a convenient solution for document upload, accurate retrieval of answers, and efficient exploration of information.
The paper focuses on a vision-language model called InstructBLIP and explores the process of instruction tuning. The authors collect 26 datasets and categorize them for instruction tuning and zero-shot evaluation. They also introduce a method called instruction-aware visual feature extraction. The results show that InstructBLIP achieves the best performance among all models, surpassing BLIP-2 and Flamingo. When fine-tuned for specific tasks, InstructBLIP exhibits exceptional accuracy, such as 90.7% on the ScienceQA IMG task. Through qualitative comparisons, the study highlights InstructBLIP's superiority over other multimodal models, demonstrating its importance in the field of vision-language tasks.
FoldFold allExpandExpand allAre you sure you want to delete this link?Are you sure you want to delete this tag?
The personal, minimalist, super-fast, database free, bookmarking service by the Shaarli community
















 (197)
(197)